6.2 Collections and Weaker Derivation RelationBundles and Documents
The statedefinitions, inferences, and constraints, and
the resulting notions of normalization, validity and equivalence,
assume a collectionPROV document that consists only of a toplevel
instance, containing all PROV statements in the top level of the
document (that is, not enclosed in a named bundle). In this
section, we describe how to deal with general PROV
documents, possibly including multiple named bundles. Briefly, each bundle is only known to the extent that a chain
handled independently; there is no interaction between bundles from
the perspective of derivations starting from an empty collection can be found. Since a
set of statements regarding a collection's evolution may be
incomplete, so is the reconstructed state obtained by querying those
statements. In general, all statements reflect partial knowledge regarding a sequence of data transformation events. In the particular case of collection evolution, in which some of the state changes may have been missed, the more generic derivation relation should be used to signal that some updates may have occurred, which cannot be expressed as insertionsapplying definitions, inferences, or removals. The following example illustrates this.
In the example, the state of c2 is only partially known because the collection is constructed from partially known other collections.
entity(c0, [prov:type="prov:EmptyCollection" %% xsd:QName]) // c0 is an empty collection
entity(c1, [prov:type="prov:Collection" %% xsd:QName])
entity(c2, [prov:type="prov:Collection" %% xsd:QName])
entity(c3, [prov:type="prov:Collection" %% xsd:QName])
entity(e1)
entity(e2)
derivedByInsertionFrom(c1, c0, {("k1", e1)})
wasDerivedFrom(c2, c1)
derivedByInsertionFrom(c3, c2, {("k2", e2)})
From this set of statements, we conclude:
c1 = { ("k1", e1) }
c2 is somehow derived from c1, but the precise sequence of updates is unknown
c3 includes ("k2", e2) but the earlier "gap" leaves uncertainty regarding ("k1", e1) (it may have been removed)constraints,
computing normal forms, or any other pair that may have been added as part of the derivation activities.
Do the insertion/removal derivation steps imply wasDerivedFrom,
wasVersionOf, alternateOf?
7. Account Constraints
Work on accounts has been deferred until after the next working draft,
so this section is very unstable
PROV-DM allows for multiple descriptions of entities (and in general any identifiable object) to be expressed.
Let us consider two statements about the same entity, which we have taken from two different contexts. A working draft published by the w3:Consortium:
entity(tr:WD-prov-dm-20111215, [ prov:type="pr:RecsWD" %% xsd:QName ])
The second version of a document edited by some authors:
entity(tr:WD-prov-dm-20111215, [ prov:type="document", ex:version="2" ])
Both statements are about the same entity identified by
tr:WD-prov-dm-20111215, but they contain different attributes, describing the situationchecking validity or partial state of the these entities according to the context in which they occur.
Two different statements about the same entity cannot co-exist in PROV instance
as formalized in entity-unique.
In some cases, there may be a requirement for two different
statements concerning the same entity to be included in the same account. To satisfy the constraint entity-unique, we can adopt a different identifier for one of them, and relate the two statements with the alternateOf relation.
We now reconsider the same two statements of a same entity, but we change the identifier for one of them:
entity(tr:WD-prov-dm-20111215, [ prov:type="pr:RecsWD" %% xsd:QName ])
entity(ex:alternate-20111215, [ prov:type="document", ex:version="2" ])
alternateOf(tr:WD-prov-dm-20111215,ex:alternate-20111215)
Since we are not specifying ways to take the union of two accounts,
we may drop this discussion
Taking the union of two accounts is another account,
formed by the union of the statements they respectively contain. We note that the resulting union may or may not invalidate some constraints:
Two entity statements with the same identifier but different sets of attributes exist in each PROV instance may invalidate entity-unique in the union, unless some form of statement merging or renaming (as per Example) occurs.
Structurally well-formed
accounts are not
closed under union because the
constraint generation-uniqueness may no
longer be satisfied in the resulting union.
How to reconcile such accounts is beyond the scope of this specification.
Material transplanted from old structural well-formedness constraints section.
This example isn't very clear, since the sub-workflow-ness isn't
represented in the data. According to what was written above, we
should conclude that a0 and a2 are equal!
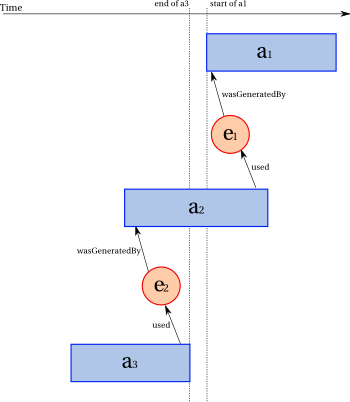
In the following statements, a workflow execution a0 consists of two sub-workflow executions a1 and a2.
Sub-workflow execution a2 generates entity e, so does a0.
activity(a0, [prov:type="workflow execution"])
activity(a1, [prov:type="workflow execution"])
activity(a2, [prov:type="workflow execution"])
wasInformedBy(a2,a1)
wasGeneratedBy(e,a0)
wasGeneratedBy(e,a2)
So, we have two different generations for entity e. Such an example is permitted in PROV-DM if the two activities denoted by a0 and a2 are a single thing happening in the world
but described from different perspectives.
While this example is permitted in PROV-DM, it does not make the inter-relation between activities explicit, and it mixes statements expressed from different perspectives together.
While this may acceptable in some specific applications, it becomes challenging for inter-operability. Indeed, PROV-DM does not offer any relation describing the structure of activities.
Such instances are said not to be structurally well-formed.equivalence.
Structurally well-formed provenance can We model a general PROV document, containing n named bundles
b1...bn, as a tuple
(B0,[b1=B1,...,bn=Bn])
where B0 is the set of
statements of the toplevel instance, and for each i, Bi is the set of
statements of bundle bi. Names b1...bn are assumed to be obtained by partitioning the generations into different accounts. distinct. This makes it clear that these generations provide alternative
descriptions of the same real-world generation event, rather than describing two distinct generation eventsnotation is shorthand for the same entity. When accounts are used, the example can be encoded as follows.
following PROV-N syntax:
The same example is now revisited, with the following statements that are structurally well-formed. Two accounts are introduced, and there is a single generation for entity e per account.
B0
bundle b1
B1
endBundle
...
bundle bn
Bn
endBundle
In The normal form of a first account, entitled "summary", we find:
activity(a0,t1,t2,[prov:type="workflow execution"])
wasGeneratedBy(e,a0,-)
In a second account, entitled "detail", we find:
activity(a1,t1,t3,[prov:type="workflow execution"])
activity(a2,t3,t2,[prov:type="workflow execution"])
wasInformedBy(a2,a1)
wasGeneratedBy(e,a2,-)
Structurally well-formed provenance satisfies some constraints, which force the structurePROV document
(B0,[b1=B1,...,[bn=Bn]) is (B'0,[b1=B'1,...,bn=B'n])
where B'i is the normal
form of statements to be exposed by means of accounts. With these constraints satisfied, further
inferences can be made about structurally well-formed statements.
The uniqueness of generations in accounts is formulated as follows.
8. RationaleBi for inferences and constraintsThis section is non-normative.
This section collects all of the explanatory
material that I was not certain how to interpret as an unambiguous
inference or constraint. Some of these observations may need to be folded
into the explanatory text in respective sections (for example for
events,
accounts or collections).
Editing is also needed to decrease redundancy.
8.1 Entities and Attributes
When we talk about things in the world in natural language and even when we assign identifiers, we are often imprecise in ways that make it difficult to clearly and unambiguously report
provenance: a resource with a URL may be understood as referring to a report available at that URL, the version of the report available there today, the report independent of where it is
hosted over time, etc.
However, to write precise descriptions of the provenance of things
that change over time, we need ways of disambiguating which versions
of things we are talking about.
To describe the provenance of things that can change over
time, PROV-DM uses the concept of entities with fixed
attributes. From a provenance viewpoint, it is important to identify
a partial state of something, i.e. something with some aspects that
have been fixed, so that it becomes possible to express its provenance
(i.e. what caused the thing with these specific aspects). An entity
encompasses a part of a thing's history during which some of the
attributes are fixed. An entity can thus be thought of as a part of a
thing with some associated partial state.
Attributes in PROV-DM are used to fix certain aspects of entities.
An entity is a thing one wants to provide provenance for
and whose situation in the world is described by some fixed
attributes. An entity has a characterization interval,
or lifetime,
defined as the period
each i between its generation event
and its invalidation event0 and n.
An entity's attributes are established when the entity is
created and describe the entity's situation and (partial) state
during an entity's lifetime.
A different entity (perhaps representing a different user or
system perspective) may fix other aspects of the same thing, and its provenance
may be different. Different entities that are aspects of the same
thing are called alternate, and the PROV-DM relations of
specialization and alternate can be used to link such entities.
Different users may take different perspectives on a resource with
a URL. A provenance record might use one (or more) different
entities to talk about different perspectives, such as:
a report available at a URL: fixes the nature of the thing, i.e. a document, and its location;
the version of the report available there today: fixes its version number, contents, and its date;
the report independent of where it is hosted and of its content over time: fixes the nature of the thing as a conceptual artifact.
The provenance of these three entities may differ, and may be along the following lines:
the provenance of a report available at a URL may include: the act of publishing it and making it available at a given location, possibly under some license and access control;
the provenance of the version of the report available there today may include: the authorship of the specific content, and reference to imported content;
the provenance of the report independent of where it is hosted over time may include: the motivation for writing the report, the overall methodology for producing it, and the broad team
involved in it.
We do not assume that any entity is a better or worse description of
reality than any other. That is, we do not assume an absolute ground truth with
respect to which we can judge correctness or completeness of
descriptions. In fact, it is possible to describe the processing that occurred for the report to be commissioned, for
individual versions to be created, for those versions to be published at the given URL, etc., each via a different entity with attribute-value pairs that fix some aspects of the report appropriately.
Besides entities, a variety of other PROV-DM objects have
attributes, including activity, generation, usage, start, end,
communication, attribution, association, responsibility, and
derivation. Each object has an associated duration interval (which may
be a single time point), and attribute-value pairs for a given object
are expected to be descriptions that hold for the object's duration.
However, the attributes of entities have special meaning because they
are considered to be fixed aspects
of underlying, changing things. This motivates constraints on
alternateOf and specializationOf relating the attribute values of
different entities.
TODO:
Constraints on alternateOf/specializationOf for this?
TODO: Further discussion of entities moved from the old "Definitional
constraints" section. Should merge with the surrounding
discussion to avoid repetition.
An entity is a thing one wants to provide provenance for
and whose situation in the world is described by some attribute-value
pairs. An entity's attribute-value pairs are established as part of
the entity statement and their values remain unchanged for the
lifetime of the entity. An entity's attribute-value pairs are expected
to describe the entity's situation and (partial) state during an
entity's characterization interval.
If an entity's situation or state changes, this may result in its statement being invalid, because one or more attribute-value pairs no longer hold. In that case, from the PROV viewpoint, there exists a new entity, which needs to be given a distinct identifier, and associated with the attribute-value pairs that reflect its new situation or state.
Further considerations:
In order to describe the provenance of something during an interval over which
relevant attributes of the thing are not fixed, it is required to
create multiple entities, each with its own identifier, characterization interval, and
fixed attributes, and express
dependencies between the various entities using events.
For example, if we want to describe the provenance of several
versions of a document, involving attributes such as authorship that
change over time, we need different entities for the versions linked
by appropriate generation, usage, revision, and invalidation events.
There is no assumption that the set of attributes is complete, nor
that the attributes are independent or orthogonal of each other.
There is no assumption that the attributes of an entity uniquely
identify it. Two different entities that are aspects of different
things can have the same attributes.
A characterization interval may collapse into a single instant.
8.2 Activities
TODO: Further discussion of activities moved from old "Definitional
constraints and inferences" section. Edit to avoid repeating information.
An activity is delimited by its start and its end events; hence, it occurs over
an interval delimited by two instantaneous
events. However, an activity record need not mention start or end time information, because they may not be known.
An activity's attribute-value pairs are expected to describe the activity's situation during its interval, i.e. an interval between two instantaneous events, namely its start event and its end event.
Further considerations:
An activity is not an entity.
Indeed, an entity exists in full at
any point in its lifetime, persists during this
interval, and preserves the characteristics that makes it
identifiable. In contrast, an activity is something that occurs, happens,
unfolds, or develops through time, but is typically not identifiable by
the characteristics it exhibits at any point during its duration.
This distinction is similar to the distinction between
'continuant' and 'occurrent' in logic [Logic].
8.3 Description, Assertion, and Inference
PROV-DM is a provenance data model designed to express descriptions of the world.
A file at some point during its lifecycle, which includes multiple edits by multiple people, can be described by its type, its location in the file system, a creator, and content.
The data model is designed to capture activities that happened in the past, as opposed to activities
that may or will happen.
However, this distinction is not formally enforced.
Therefore, PROV-DM descriptions are intended to be interpreted as what
has happened, as opposed to what may or will happen.
This specification does not prescribe the means by which descriptions can be arrived at; for example, descriptions can be composed on the basis of observations, reasoning, or any other means.
Sometimes, inferences about the world can be made from descriptions
conformant to the PROV-DM data model. This
specification defines some such inferences, allowing new descriptions
to be inferred from existing ones. Hence, descriptions of the world
can result either from direct assertion or from inference
by application of inference rules defined by this specification.
8.4 Events and Time
Time is critical in the context of provenance, since it can help corroborate provenance claims. For instance, if an entity is claimed to be obtained by transforming another, then the
latter must have existed before the former. If it is not the case, then there is something wrong with such a provenance claim.
Although time is critical, we should also recognize that
provenance can be used in many different contexts within individual
systems and across the Web. Different systems may use different clocks
which may not be precisely synchronized, so when provenance records
are combined by different systems, we may not be able to align the
times involved to a single global timeline. Hence, PROV-DM is
designed to minimize assumptions about time.
Hence, to talk about the constraints on valid PROV-DM data, we
refer to instantaneous events that correspond to interactions
between activities and entities.
The term "event" is commonly used in process algebra with a similar meaning. For instance, in CSP [CSP], events represent communications or interactions; they are assumed to be atomic and
instantaneous.
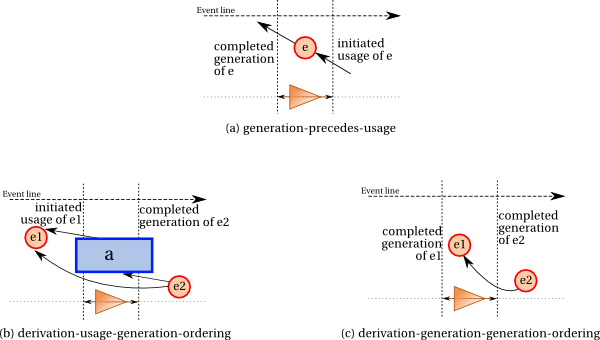
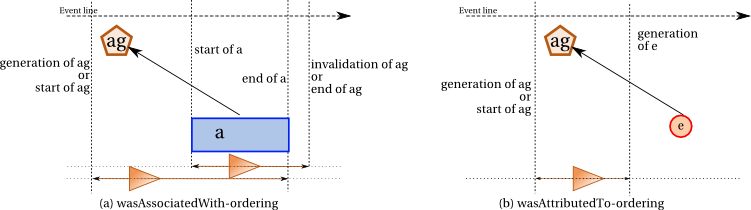
8.4.1 Event Ordering
The following paragraphs are unclear and need to be revised, to
address review concerns: if
we aren't saying anything about how events and time relate, and time
is the only concrete information about event ordering in PROV-DM,
then how can implementations check that event ordering constraints
are satisfied?
How the precedes partial order is implemented in practice is beyond the scope
of this specification. This specification only assumes that
each instantaneous event can be mapped to an instant in some form of
timeline. The actual mapping is not in scope of this
specification. Likewise, whether this timeline is formed of a single
global timeline or whether it consists of multiple Lamport-style
clocks is also beyond this specification. The follows and
precedes orderings of events should be consistent with the
ordering of their associated times
over these timelines.
This specification defines event ordering constraints
between instantaneous events associated with
provenance descriptions. PROV-DM data must satisfy such constraints.
PROV-DM also allows for time observations to be inserted in
specific statements, forA PROV document is valid if each recognized instantaneous event introduced in this
specification. The presence of a time observation for a given instantaneous event fixes the mappingthe bundles B0,
..., Bn are valid and none of this instantaneous event to the timeline. It can also
help with the verification of associated ordering constraints (though,
again, this verification is outside the scope of this specification).
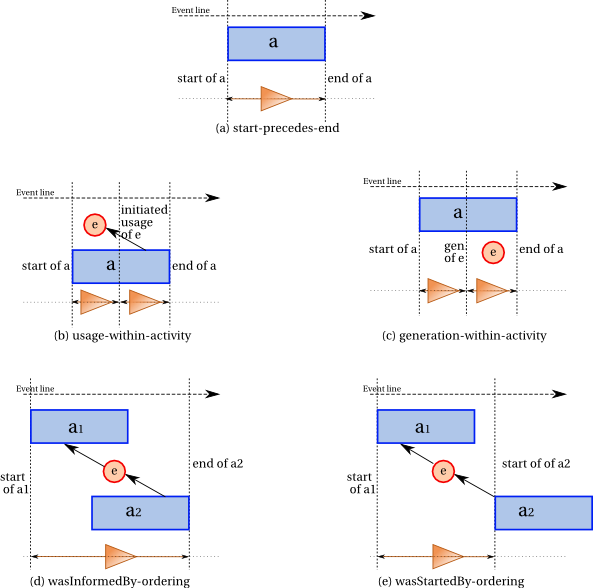
8.4.2 Types of Events
Five kinds of instantaneous eventsthe bundle identifiers bi are used
for the PROV-DM data model. The activity start and
activity end events delimit the beginning and the end
of activities, respectively. The entity usage,
entity generation, and entity
invalidation events apply to entities, and the generation and
invalidation events delimit the characterization interval of
an entity. More specifically:
repeated.
An activity start eventTwo (valid) PROV documents (B0,[b1=B1,...,bn=Bn]) and
(B'0,[b1'=B'1,...,b'm=B'm]) are equivalent if B0 is the instantaneous event
equivalent to B'0 and n = m and
there exists a permutation P : {1..n} -> {1..n} such that marks the instant an activity starts.
An activity end eventfor each i, bi =
b'P(i) and Bi is the instantaneous event that marks the instant an activity ends.
An entity usage event is the instantaneous event that marks the first instant of
an entity's consumption timespan by an activity. Before this instant
the entity had not begunequivalent to be used by the activity.
An entity generation event is the instantaneous event that marks the final instant of an entity's creation timespan, after which
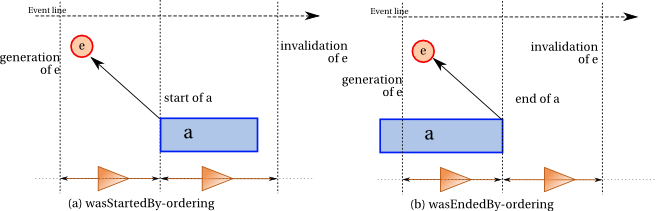
it is available for use. The entity did not exist before this event.
An entity invalidation event
is the instantaneous event that
marks the initial instant of the destruction, invalidation, or
cessation of an entity, after which the entity is no longer available
for use. The entity no longer exists after this event.B'P(i).