A global distributed Social Web requires that each person be able to
control their identity, that this identity be linkable across sites -
placing each person in a Web of relationships - and that it be possible to
authenticate globally with such identities.
This specification outlines a simple universal identification mechanism
that is distributed, openly extensible, improves privacy, security and
control over how each person can identify themselves in order to allow fine
grained access control to their information on the Web.
It does this by applying the best practices of Web Architecture whilst
building on well established widely deployed protocols and standards
including HTML, URIs, HTTP, and RDF Semantics.
How to Read this Document
There are a number of concepts that are covered in this document that the
reader may want to be aware of before continuing. General knowledge of RDF
[[!RDF-PRIMER]] is necessary to understand how to implement this specification.
WebID uses a number of specific technologies like Turtle [[!turtle]] and RDFa
[[!RDFA-CORE]].
A general Introduction is provided for all that
would like to understand why this specification is necessary to simplify usage
of the Web.
The terms used throughout this specification are listed in the section
titled Terminology.
This document is produced from work by the
W3C WebID Community Group.
This is an internal draft document and may not even end up being officially
published. It may also be updated, replaced or obsoleted by other documents
at any time. It is inappropriate to cite this document as other than work in progress.
The source code for this document is available at the following
URI: https://dvcs.w3.org/hg/WebID
Terminology
This section provides definitions for several important terms used in this document.
- Requesting Agent
- The Requesting Agent initiates a request to a Service listening on a specific port using a given protocol on a given Server.
- Server
- A Server is a machine contactable at a domain name or IP address that hosts a number of globally accessible Services.
- Service
- A Service is an agent listening for requests at a given IP address on a given Server.
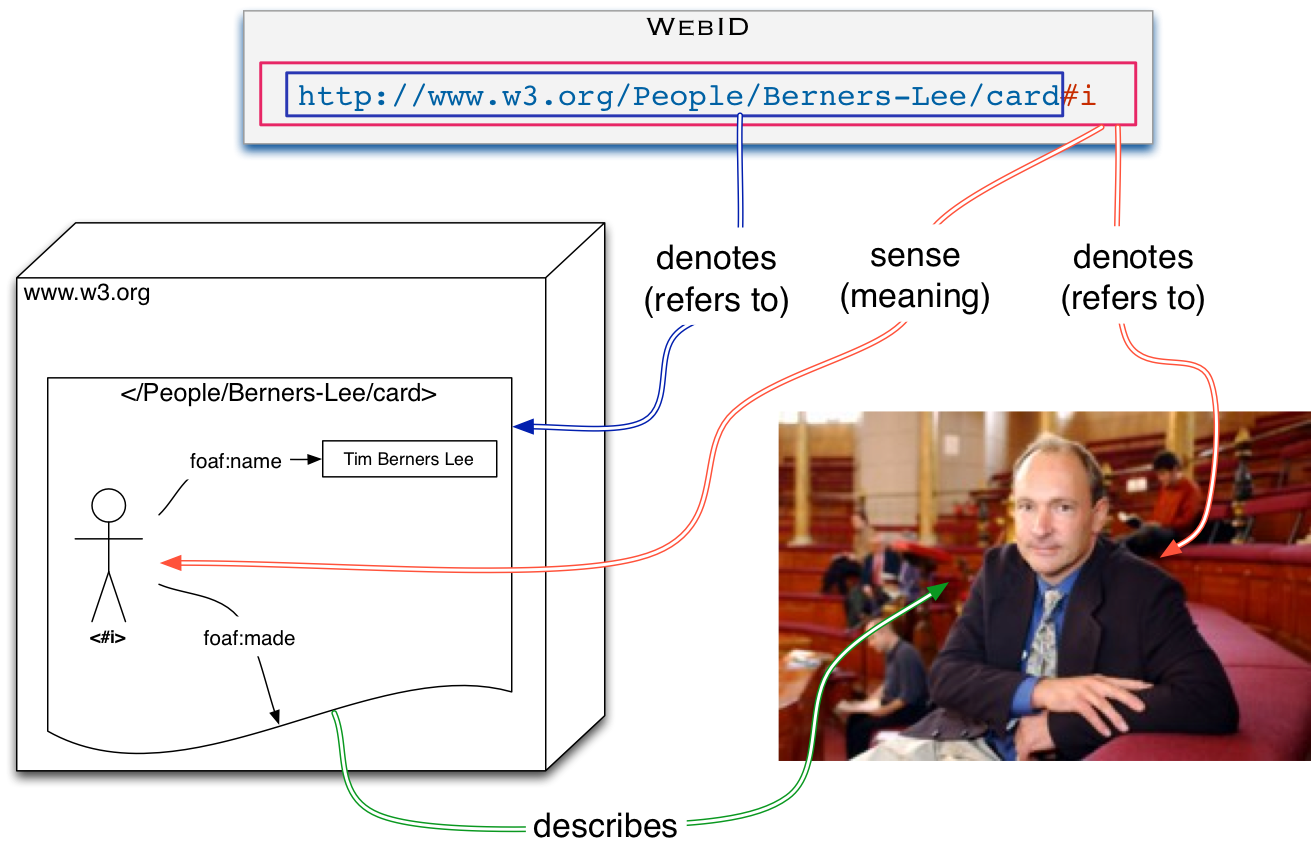
- WebID
- A WebID is a URI with an HTTP or HTTPS scheme which denotes an Agent (Person, Organization, Group, Device, etc.). For WebIDs with fragment identifiers (e.g. #me), the URI without the fragment denotes the Profile Document. For WebIDs without fragment identifiers an HTTP request on the WebID MUST return a 303 with a Location header URI referring to the Profile Document.
- WebID Profile or Profile Document
-
A WebID Profile is an RDF document which uniquely describes the Agent denoted by the WebID in relation to that WebID. The server MUST provide a
text/turtle [[!turtle]] representation of the requested profile. This document MAY be available in other RDF serialization formats, such as RDFa [[!RDFA-CORE]], or [[!RDF-SYNTAX-GRAMMAR]] if so requested through content negotiation.
Namespaces
Examples assume the following namespace prefix bindings unless otherwise stated:
| Prefix |
IRI |
foaf |
http://xmlns.com/foaf/0.1/ |
The WebID HTTP URI
When using URIs, it is possible to identify both a thing (which may exist outside of the Web) and a Web document describing the thing. For example, the person Bob is described on his homepage. Alice may not like the look of the homepage, but may want to link to the person Bob. Therefore, two URIs are needed, one for Alice and one for the homepage or a RDF document describing Alice.
The WebID HTTP URI must be one that dereferences to a document the user controls.
For example, if a user Bob controls https://bob.example.org/profile,
then his WebID can be https://bob.example.org/profile#me.
There are two solutions that meet our requirements for identifying real-world objects: 303 redirects and hash URIs. Which one to use depends on the situation, both have advantages and disadvantages, as presented in [[!COOLURIS]]. All examples in this specification will use such hash URIs.
Publishing the WebID Profile Document
WebID requires that servers MUST at least be able to provide Turtle representation of profile documents, but other serialization formats of the graph are allowed, provided that agents are able to parse that serialization and obtain the graph automatically.
HTTP Content Negotiation can be employed to aid in publication and discovery of multiple distinct serializations of the same graph at the same URL, as explained in [[!COOLURIS]]
It is particularly useful to have one of the representations be in HTML
even if it is not marked up in RDFa as this allows people using a
web browser to understand what the information at that URI represents.
WebID Profile Vocabulary
WebID RDF graphs are built using vocabularies identified by URIs, that can be placed in subject, predicate or object position of the relations constituting the graph.
The definition of each URI should be found at the namespace of the URI, by dereferencing it.
Processing the WebID Profile
The Requesting Agent needs to fetch the document, if it does not have a valid one in cache.
The Agent requesting the WebID document MUST be able to parse documents in Turtle [[!turtle]], but MAY also be able to parse documents in RDF/XML [[!RDF-SYNTAX-GRAMMAR]] and RDFa [[!RDFA-CORE]].
The result of this processing should be a graph of RDF relations that is queryable, as explained in the next section.
It is recommended that the Requesting Agent sets a qvalue for text/turtle in the HTTP Accept-Header with a higher priority than in the case of application/xhtml+xml or text/html, as sites may produce HTML without RDFa markup but with a link to graph encoded in a pure RDF format such as Turtle.
For an agent that can parse Turtle, rdf/xml and RDFa, the following would be a reasonable Accept header:
Accept: text/turtle,application/rdf+xml,application/xhtml+xml;q=0.8,text/html;q=0.7
If the Requesting Agent wishes to have the most up-to-date Profile document for an HTTP URL, it can use the HTTP cache control headers to get the latest versions.