An XML Syntax for RDF
This section introduces the RDF/XML syntax, describes how it encodes RDF graphs and explains this with examples. If there is any conflict between this informal description and the formal description of the syntax and grammar in sections 6 Syntax Data Model and 7 RDF/XML Grammar, the latter two sections take precedence.
Introduction
The RDF Concepts and Abstract Syntax document [[RDF11-CONCEPTS]] defines the RDF Graph data model and the RDF Graph abstract syntax. Along with the RDF Semantics [[RDF11-MT]] this provides an abstract syntax with a formal semantics for it. The RDF graph has nodes and labeled directed arcs that link pairs of nodes and this is represented as a set of RDF triples where each triple contains a subject node, predicate and object node. Nodes are IRIs, literals, or blank nodes. Blank nodes may be given a document-local identifier called a blank node identifier. Predicates are IRIs and can be interpreted as either a relationship between the two nodes or as defining an attribute value (object node) for some subject node.
In order to encode the graph in XML, the nodes and predicates have to be represented in XML terms — element names, attribute names, element contents and attribute values. RDF/XML uses XML QNames as defined in Namespaces in XML [[!XML-NAMES]] to represent IRIs. All QNames have a namespace name which is an IRI and a short local name. In addition, QNames can either have a short prefix or be declared with the default namespace declaration and have none (but still have a namespace name)
The IRI represented by a QName is determined by appending the local name part of the QName after the namespace name (IRI) part of the QName. This is used to shorten the IRI of all predicates and some nodes. IRIs identifying subject and object nodes can also be stored as XML attribute values. RDF literals which can only be object nodes, become either XML element text content or XML attribute values.
A graph can be considered a collection of paths of the form node, predicate arc, node, predicate arc, node, predicate arc, ... node which cover the entire graph. In RDF/XML these turn into sequences of elements inside elements which alternate between elements for nodes and predicate arcs. This has been called a series of node/arc stripes. The node at the start of the sequence turns into the outermost element, the next predicate arc turns into a child element, and so on. The stripes generally start at the top of an RDF/XML document and always begin with nodes.
Several RDF/XML examples are given in the following sections building up to complete RDF/XML documents. Example 7 is the first complete RDF/XML document.
Node Elements and Property Elements
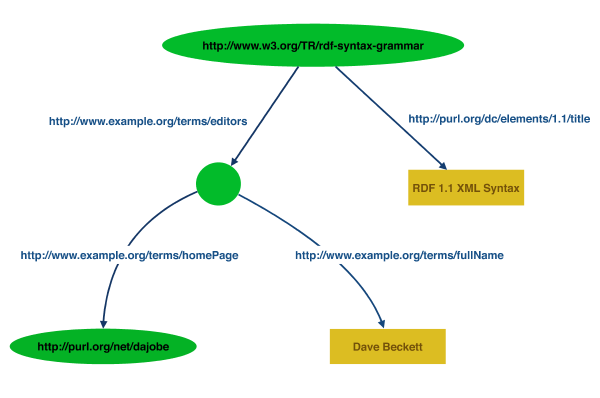
An RDF graph is given in Figure 1 where the nodes are represented as ovals and contain their IRIs where they have them, all the predicate arcs are labeled with IRIs and string literals nodes have been written in rectangles.
If we follow one node, predicate arc ... , node path through the graph shown in Figure 2:
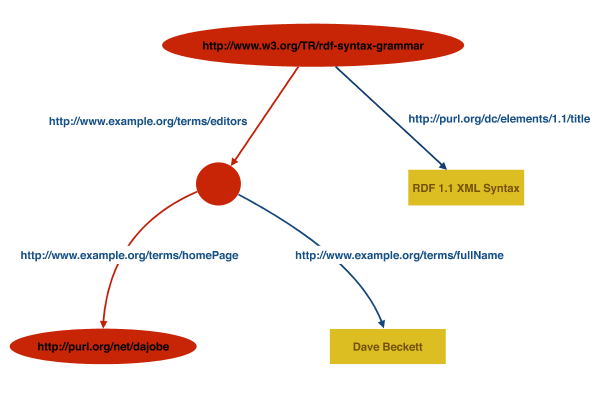
The left hand side of the Figure 2 graph corresponds to the node/predicate arc stripes:
- Node with IRI
http://www.w3.org/TR/rdf-syntax-grammar - Predicate Arc labeled with IRI
http://example.org/terms/editor - Node with no IRI
- Predicate Arc labeled with IRI
http://example.org/terms/homePage - Node with IRI
http://purl.org/net/dajobe/
In RDF/XML, the sequence of 5 nodes and predicate arcs on
the left hand side of Figure 2 corresponds to
the usage of five XML elements of two types, for the graph nodes and
predicate arcs. These are conventionally called node elements and
property elements respectively. In the striping shown in
Example 1, rdf:Description is the
node element (used three times for the three nodes) and
ex:editor and ex:homePage are the two
property elements.
Striped RDF/XML (nodes and predicate arcs)<rdf:Description><ex:editor><rdf:Description><ex:homePage><rdf:Description></rdf:Description></ex:homePage></rdf:Description></ex:editor></rdf:Description>
The Figure 2 graph consists of some nodes
that are
IRIs
(and others that are not) and this can be added
to the RDF/XML using the rdf:about attribute on node
elements to give the result in Example 2:
Node Elements with IRIs added
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description rdf:about="http://purl.org/net/dajobe/">
</rdf:Description>
</ex:homePage>
</rdf:Description>
</ex:editor>
</rdf:Description>
Adding the other two paths through the Figure 1 graph to the RDF/XML in Example 2 gives the result in Example 3 (this example fails to show that the blank node is shared between the two paths, see 2.10):
Complete description of all graph paths
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description rdf:about="http://purl.org/net/dajobe/">
</rdf:Description>
</ex:homePage>
</rdf:Description>
</ex:editor>
</rdf:Description>
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:fullName>Dave Beckett</ex:fullName>
</rdf:Description>
</ex:editor>
</rdf:Description>
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<dc:title>RDF 1.1 XML Syntax</dc:title>
</rdf:Description>
Multiple Property Elements
There are several abbreviations that can be used to make common uses easier to write down. In particular, it is common that a subject node in the RDF graph has multiple outgoing predicate arcs. RDF/XML provides an abbreviation for the corresponding syntax when a node element about a resource has multiple property elements. This can be abbreviated by using multiple child property elements inside the node element describing the subject node.
Taking Example 3, there are
two node elements that can take multiple property elements.
The subject node with IRI
http://www.w3.org/TR/rdf-syntax-grammar
has property elements ex:editor and ex:title
and the node element for the blank node can take ex:homePage
and ex:fullName. This abbreviation
gives the result shown in Example 4
(this example does show that there is a single blank node):
Using multiple property elements on a node element
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description rdf:about="http://purl.org/net/dajobe/">
</rdf:Description>
</ex:homePage>
<ex:fullName>Dave Beckett</ex:fullName>
</rdf:Description>
</ex:editor>
<dc:title>RDF 1.1 XML Syntax</dc:title>
</rdf:Description>
Empty Property Elements
When a predicate arc in an RDF graph points to an object node which has no
further predicate arcs, which appears in RDF/XML as an empty node element
<rdf:Description rdf:about="...">
</rdf:Description>
(or <rdf:Description rdf:about="..." />)
this form can be shortened. This is done by using the
IRI of the object node as the value of an XML attribute rdf:resource
on the containing property element and making the property element empty.
In this example, the property element ex:homePage
contains an empty node element with the
IRI
http://purl.org/net/dajobe/. This can be replaced with
the empty property element form giving the result shown in
Example 5:
Empty property elements
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
<ex:fullName>Dave Beckett</ex:fullName>
</rdf:Description>
</ex:editor>
<dc:title>RDF 1.1 XML Syntax</dc:title>
</rdf:Description>
Property Attributes
When a property element's content is string literal,
it may be possible to use it as an XML attribute on the
containing node element.
This can be done for multiple properties on the same node element
only if the property element name is not repeated
(required by XML — attribute names are unique on an XML element)
and any in-scope xml:lang on the
property element's string literal (if any) are the same (see
Section 2.7)
This abbreviation is known as a Property Attribute
and can be applied to any node element.
This abbreviation can also be used when the property element is
rdf:type and it has an rdf:resource attribute
the value of which is interpreted as a
IRI object node.
In Example 5:,
there are two property elements with string literal content,
the dc:title and ex:fullName
property elements. These can be replaced with property attributes
giving the result shown in Example 6:
Replacing property elements with string literal content into property attributes
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF 1.1 XML Syntax">
<ex:editor>
<rdf:Description ex:fullName="Dave Beckett">
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
</rdf:Description>
</ex:editor>
</rdf:Description>
Completing the Document: Document Element and XML Declaration
To create a complete RDF/XML document, the serialization of the
graph into XML is usually contained inside an rdf:RDF
XML element which becomes the top-level XML document element.
Conventionally the rdf:RDF element is also used to
declare the XML namespaces that are used, although that is not
required. When there is only one top-level node element inside
rdf:RDF, the rdf:RDF can be omitted
although any XML namespaces must still be declared.
The XML specification also permits an XML declaration at the top of the document with the XML version and possibly the XML content encoding. This is optional but recommended.
Completing the RDF/XML could be done for any of the correct complete graph examples from Example 4 onwards but taking the smallest Example 6 and adding the final components, gives a complete RDF/XML representation of the original Figure 1 graph in Example 7:
Complete RDF/XML description of Figure 1 graph
(example07.rdf, output example07.nt)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF1.1 XML Syntax">
<ex:editor>
<rdf:Description ex:fullName="Dave Beckett">
<ex:homePage rdf:resource="http://purl.org/net/dajobe/" />
</rdf:Description>
</ex:editor>
</rdf:Description>
</rdf:RDF>
It is possible to omit rdf:RDF in
Example 7 above since there is only one
rdf:Description inside rdf:RDF but this
is not shown here.
Languages: xml:lang
RDF/XML permits the use of the xml:lang attribute as defined by
2.12 Language Identification
of XML 1.0 [[!XML10]]
to allow the identification of content language.
The xml:lang attribute can be used on any node element or property element
to indicate that the included content is in the given language.
Typed literals
which includes XML literals
are not affected by this attribute.
The most specific in-scope language present
(if any) is applied to property element string literal content or
property attribute values. The xml:lang="" form
indicates the absence of a language identifier.
Some examples of marking content languages for RDF properties are shown in Example 8:
Complete example of xml:lang
(example08.rdf, output example08.nt)
<?xml version="1.0" encoding="utf-8"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<dc:title>RDF 1.1 XML Syntax</dc:title>
<dc:title xml:lang="en">RDF 1.1 XML Syntax</dc:title>
<dc:title xml:lang="en-US">RDF 1.1 XML Syntax</dc:title>
</rdf:Description>
<rdf:Description rdf:about="http://example.org/buecher/baum" xml:lang="de">
<dc:title>Der Baum</dc:title>
<dc:description>Das Buch ist außergewöhnlich</dc:description>
<dc:title xml:lang="en">The Tree</dc:title>
</rdf:Description>
</rdf:RDF>
XML Literals: rdf:parseType="Literal"
RDF allows XML literals [RDF11-CONCEPTS]
to be given as the object node of a predicate.
These are written in RDF/XML as content of a property element (not
a property attribute) and indicated using the
rdf:parseType="Literal" attribute on the containing
property element.
An example of writing an XML literal is given in
Example 9 where
there is a single RDF triple with the subject node
IRI
http://example.org/item01, the predicate
IRI
http://example.org/stuff/1.0/prop (from
ex:prop) and the object node with XML literal
content beginning a:Box.
Complete example of rdf:parseType="Literal"
(example09.rdf, output example09.nt)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://example.org/item01">
<ex:prop rdf:parseType="Literal" xmlns:a="http://example.org/a#">
<a:Box required="true">
<a:widget size="10" />
<a:grommit id="23" />
</a:Box>
</ex:prop>
</rdf:Description>
</rdf:RDF>
Typed Literals: rdf:datatype
RDF allows typed literals
to be given as the object node of a predicate. Typed literals consist of a literal
string and a datatype
IRI. These are written in RDF/XML using
the same syntax for literal string nodes in the property element form
(not property attribute) but with an additional
rdf:datatype="datatypeURI"
attribute on the property element. Any
IRI can be used in the attribute.
An example of an RDF typed
literal
is given in Example 10 where
there is a single RDF triple with the subject node
IRI
http://example.org/item01, the predicate
IRI
http://example.org/stuff/1.0/size (from
ex:size) and the object node with the
typed literal
("123", http://www.w3.org/2001/XMLSchema#int)
to be interpreted as an
XML Schema [[!XMLSCHEMA-2]] datatype int.
Complete example of rdf:datatype
(example10.rdf, output example10.nt)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://example.org/item01">
<ex:size rdf:datatype="http://www.w3.org/2001/XMLSchema#int">123</ex:size>
</rdf:Description>
</rdf:RDF>
Identifying Blank Nodes: rdf:nodeID
Blank nodes in the RDF graph are distinct but have no
IRI identifier.
It is sometimes required that the same graph blank node is referred to in the
RDF/XML in multiple places, such as at the subject and object
of several RDF triples. In this case, a blank node identifier
can be given to the blank node for identifying it
in the document. Blank node identifiers in RDF/XML are scoped to the
containing XML Information Set
document information item.
A blank node identifier is used
on a node element to replace
rdf:about="IRI"
or on a property element to replace
rdf:resource="IRI"
with rdf:nodeID="blank node identifier"
in both cases.
Taking Example 7 and explicitly giving
a blank node identifier of abc to the blank node in it
gives the result shown in Example 11.
The second rdf:Description property element is
about the blank node.
Complete RDF/XML description of graph using rdf:nodeID identifying the blank node
(example11.rdf, output example11.nt)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF 1.1 XML Syntax">
<ex:editor rdf:nodeID="abc"/>
</rdf:Description>
<rdf:Description rdf:nodeID="abc" ex:fullName="Dave Beckett">
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
</rdf:Description>
</rdf:RDF>
Omitting Blank Nodes: rdf:parseType="Resource"
Blank nodes (not IRI nodes) in RDF graphs can be written
in a form that allows the
<rdf:Description>
</rdf:Description> pair to be omitted.
The omission is done by putting an
rdf:parseType="Resource"
attribute on the containing property element
that turns the property element into a property-and-node element,
which can itself have both property elements and property attributes.
Property attributes and the rdf:nodeID attribute
are not permitted on property-and-node elements.
Taking the earlier Example 7,
the contents of the ex:editor property element
could be alternatively done in this fashion to give
the form shown in Example 12:
Complete example using rdf:parseType="Resource"
(example12.rdf, output: example12.nt)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF 1.1 XML Syntax">
<ex:editor rdf:parseType="Resource">
<ex:fullName>Dave Beckett</ex:fullName>
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
</ex:editor>
</rdf:Description>
</rdf:RDF>
Omitting Nodes: Property Attributes on an empty Property Element
If all of the property elements on a blank node element have
string literal values with the same in-scope xml:lang
value (if present) and each of these property elements appears at
most once and there is at most one rdf:type property
element with a IRI object node, these can be abbreviated by
moving them to be property attributes on the containing property
element which is made an empty element.
Taking the earlier Example 5,
the ex:editor property element contains a
blank node element with two property elements
ex:fullname and ex:homePage.
ex:homePage is not suitable here since it
does not have a string literal value, so it is being
ignored for the purposes of this example.
The abbreviated form removes the ex:fullName property element
and adds a new property attribute ex:fullName with the
string literal value of the deleted property element
to the ex:editor property element.
The blank node element becomes implicit in the now empty
ex:editor property element. The result is shown in
Example 13.
Complete example of property attributes on an empty property element
(example13.rdf, output example13.nt)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF 1.1 XML Syntax">
<ex:editor ex:fullName="Dave Beckett" />
<!-- Note the ex:homePage property has been ignored for this example -->
</rdf:Description>
</rdf:RDF>
Typed Node Elements
It is common for RDF graphs to have rdf:type predicates
from subject nodes. These are conventionally called typed
nodes in the graph, or typed node elements in the
RDF/XML. RDF/XML allows this triple to be expressed more concisely.
by replacing the rdf:Description node element name with
the namespaced-element corresponding to the
IRI of the value of
the type relationship. There may, of course, be multiple rdf:type
predicates but only one can be used in this way, the others must remain as
property elements or property attributes.
The typed node elements are commonly used in RDF/XML with the built-in
classes in the RDF vocabulary:
rdf:Seq, rdf:Bag, rdf:Alt,
rdf:Statement, rdf:Property and
rdf:List.
For example, the RDF/XML in Example 14 could be written as shown in Example 15.
Complete example with rdf:type
(example14.rdf, output example14.nt)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://example.org/thing">
<rdf:type rdf:resource="http://example.org/stuff/1.0/Document"/>
<dc:title>A marvelous thing</dc:title>
</rdf:Description>
</rdf:RDF>
Complete example using a typed node element to replace an rdf:type
(example15.rdf, output example15.nt)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<ex:Document rdf:about="http://example.org/thing">
<dc:title>A marvelous thing</dc:title>
</ex:Document>
</rdf:RDF>
Abbreviating URIs: rdf:ID and xml:base
RDF/XML allows further abbreviating IRIs in XML attributes in two
ways. The XML Infoset provides a base URI attribute xml:base
that sets the base URI for resolving relative IRIs, otherwise
the base URI is that of the document. The base URI applies to
all RDF/XML attributes that deal with IRIs which are rdf:about,
rdf:resource, rdf:ID
and rdf:datatype.
The rdf:ID attribute on a node element (not property
element, that has another meaning) can be used instead of
rdf:about and gives a relative IRI equivalent to #
concatenated with the rdf:ID attribute value. So for
example if rdf:ID="name", that would be equivalent
to rdf:about="#name". rdf:ID provides an additional
check since the same name can only appear once in the
scope of an xml:base value (or document, if none is given),
so is useful for defining a set of distinct,
related terms relative to the same IRI.
Both forms require a base URI to be known, either from an in-scope
xml:base or from the URI of the RDF/XML document.
Example 16 shows abbreviating the node
IRI of http://example.org/here/#snack using an
xml:base of http://example.org/here/ and
an rdf:ID on the rdf:Description node element.
The object node of the ex:prop predicate is an
absolute IRI
resolved from the rdf:resource XML attribute value
using the in-scope base URI to give the
IRI http://example.org/here/fruit/apple.
Complete example usingrdf:IDandxml:basefor shortening URIs (example16.rdf, output example16.nt) <?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ex="http://example.org/stuff/1.0/" xml:base="http://example.org/here/"> <rdf:Description rdf:ID="snack"> <ex:prop rdf:resource="fruit/apple"/> </rdf:Description> </rdf:RDF>
Container Membership Property Elements: rdf:li and rdf:_n
RDF has a set of container membership properties
and corresponding property elements that are mostly used with
instances of the
rdf:Seq, rdf:Bag and rdf:Alt
classes which may be written as typed node elements. The list properties are
rdf:_1, rdf:_2 etc. and can be written
as property elements or property attributes as shown in
Example 17. There is an rdf:li
special property element that is equivalent to
rdf:_1, rdf:_2 in order,
explained in detail in section 7.4.
The mapping to the container membership properties is
always done in the order that the rdf:li special
property elements appear in XML — the document order is significant.
The equivalent RDF/XML to Example 17 written
in this form is shown in Example 18.
Complex example using RDF list properties
(example17.rdf, output example17.nt)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Seq rdf:about="http://example.org/favourite-fruit">
<rdf:_1 rdf:resource="http://example.org/banana"/>
<rdf:_2 rdf:resource="http://example.org/apple"/>
<rdf:_3 rdf:resource="http://example.org/pear"/>
</rdf:Seq>
</rdf:RDF>
Complete example using rdf:li property element for list properties
(example18.rdf, output example18.nt)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Seq rdf:about="http://example.org/favourite-fruit">
<rdf:li rdf:resource="http://example.org/banana"/>
<rdf:li rdf:resource="http://example.org/apple"/>
<rdf:li rdf:resource="http://example.org/pear"/>
</rdf:Seq>
</rdf:RDF>
Collections: rdf:parseType="Collection"
RDF/XML allows an rdf:parseType="Collection"
attribute on a property element to let it contain multiple node
elements. These contained node elements give the set of subject
nodes of the collection. This syntax form corresponds to a set of
triples connecting the collection of subject nodes, the exact triples
generated are described in detail in
Section 7.2.19 Production parseTypeCollectionPropertyElt.
The collection construction is always done in the order that the node
elements appear in the XML document. Whether the order of the
collection of nodes is significant is an application issue and not
defined here.
Example 19 shows a collection of three
nodes elements at the end of the ex:hasFruit
property element using this form.
Complete example of a RDF collection of nodes using rdf:parseType="Collection"
(example19.rdf, output example19.nt)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://example.org/basket">
<ex:hasFruit rdf:parseType="Collection">
<rdf:Description rdf:about="http://example.org/banana"/>
<rdf:Description rdf:about="http://example.org/apple"/>
<rdf:Description rdf:about="http://example.org/pear"/>
</ex:hasFruit>
</rdf:Description>
</rdf:RDF>
Reifying Statements: rdf:ID
The rdf:ID attribute can be used on a property
element to reify the triple that it generates (See
section 7.3 Reification Rules for the
full details).
The identifier for the triple should be constructed as a
IRI
made from the relative IRI
# concatenated with the rdf:ID attribute
value, resolved against the in-scope base URI. So for example if
rdf:ID="triple", that would be equivalent to the IRI
formed from relative IRI #triple against the base URI.
Each (rdf:ID attribute value, base URI)
pair has to be unique in an RDF/XML document,
see constraint-id.
Example 20 shows a rdf:ID
being used to reify a triple made from the ex:prop
property element giving the reified triple the
IRI http://example.org/triples/#triple1.
Complete example of rdf:ID reifying a property element
(example20.rdf, output example20.nt)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/"
xml:base="http://example.org/triples/">
<rdf:Description rdf:about="http://example.org/">
<ex:prop rdf:ID="triple1">blah</ex:prop>
</rdf:Description>
</rdf:RDF>
{kind=link}
{kind=link}