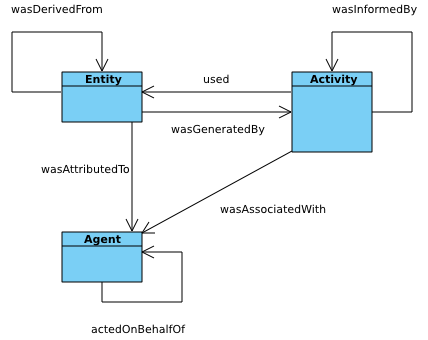
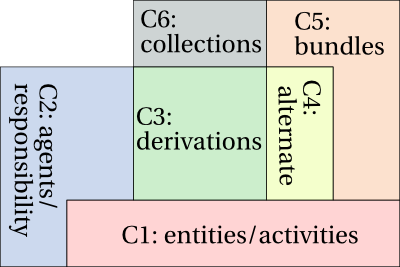
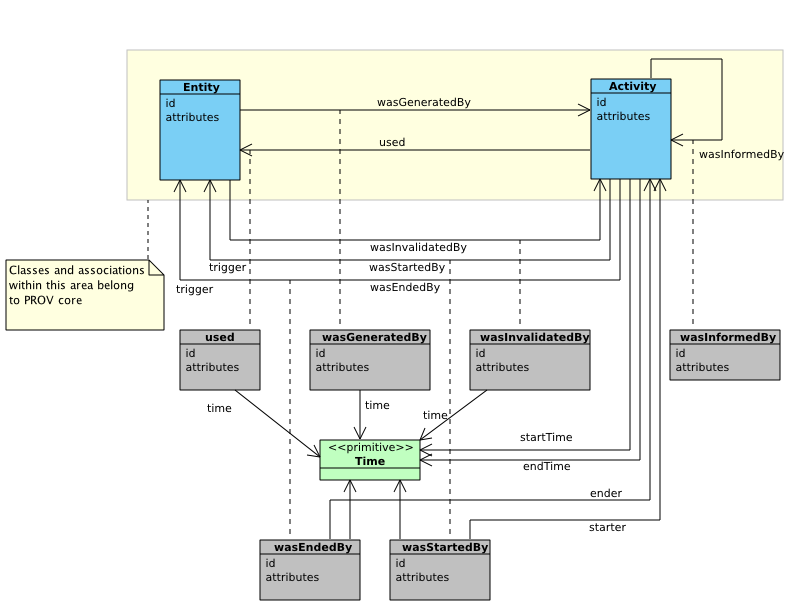
The fifth component of PROV-DM is concerned with bundles, a mechanism to support provenance of provenance.
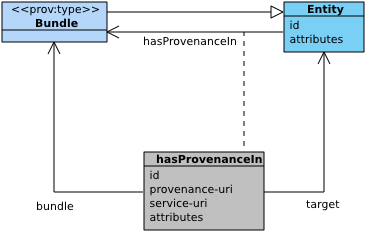
Figure 9 depict a UML class diagram for the fifth component. It comprises a Bundle class, a subclass of Entity and a novel n-ary relation, Provenance Locator.
5.5.2 Bundle Description
A bundle is a named set of descriptions, but it is also an entity so that its provenance can be described.
PROV defines the following type for bundles:
- prov:Bundle is the type that denotes bundles.
A bundle description is of the form entity(id,[prov:type='prov:Bundle', attr1=val1, ...])
where id is an identifier denoting a bundle,
a type prov:Bundle and
an optional set of attribute-value pairs ((attr1, val1), ...) representing additional information about this bundle.
The provenance of provenance can then be described using PROV constructs, as illustrated by
Example 43
and
Example 44.
Let us consider two entities ex:report1 and ex:report2.
entity(ex:report1, [ prov:type="report", ex:version=1 ])
wasGeneratedBy(ex:report1, -, 2012-05-24T10:00:01)
entity(ex:report2, [ prov:type="report", ex:version=2])
wasGeneratedBy(ex:report2, -, 2012-05-25T11:00:01)
wasDerivedFrom(ex:report2, ex:report1)
Let us assume that Bob observed the creation of ex:report1.
A first bundle can be expressed.
bundle bob:bundle1
entity(ex:report1, [ prov:type="report", ex:version=1 ])
wasGeneratedBy(ex:report1, -, 2012-05-24T10:00:01)
endBundle
In contrast,
Alice observed the creation of ex:report2 and its derivation from ex:report1.
A separate bundle can also be expressed.
bundle alice:bundle2
entity(ex:report1)
entity(ex:report2, [ prov:type="report", ex:version=2 ])
wasGeneratedBy(ex:report2, -, 2012-05-25T11:00:01)
wasDerivedFrom(ex:report2, ex:report1)
endBundle
The first bundle contains the descriptions corresponding to Bob observing the creation of ex:report1. Its provenance can be described as follows.
entity(bob:bundle1, [prov:type='prov:Bundle'])
wasGeneratedBy(bob:bundle1, -, 2012-05-24T10:30:00)
wasAttributedTo(bob:bundle1, ex:Bob)
In contrast, the second bundle is attributed to Alice who
observed the derivation of ex:report2 from ex:report1.
entity(alice:bundle2, [ prov:type='prov:Bundle' ])
wasGeneratedBy(alice:bundle2, -, 2012-05-25T11:15:00)
wasAttributedTo(alice:bundle2, ex:Alice)
A provenance aggregator could merge two bundles, resulting in a novel bundle, whose provenance is described as follows.
bundle agg:bundle3
entity(ex:report1, [ prov:type="report", ex:version=1 ])
wasGeneratedBy(ex:report1, -, 2012-05-24T10:00:01)
entity(ex:report2, [ prov:type="report", ex:version=2 ])
wasGeneratedBy(ex:report2, -, 2012-05-25T11:00:01)
wasDerivedFrom(ex:report2, ex:report1)
endBundle
entity(agg:bundle3, [ prov:type='prov:Bundle' ])
agent(ex:aggregator01, [ prov:type='ex:Aggregator' ])
wasAttributedTo(agg:bundle3, ex:aggregator01)
wasDerivedFrom(agg:bundle3, bob:bundle1)
wasDerivedFrom(agg:bundle3, alice:bundle2)
The new bundle is given a new identifier agg:bundle3 and is attributed to the ex:aggregator01 agent.
5.5.3 Provenance Locator
In
Example 43, we initially presented a scenario involving two entities
report1 and
report2, and showed how their descriptions can be organized into two bundles. There is no explicit indication that the second bundle "is a continuation" of the description offered by the first bundle. Given that bundles may be retrieved separately [
PROV-AQ], it is not obvious for a provenance consumer to navigate descriptions across bundles. To aid consumers,
Alice may wish to express that there is further provenance information about
report1 in bundle
bob:bundle1. To this end, PROV introduces the notion of provenance locator, inspired by [
PROV-AQ].
A provenance locator is information that helps locate provenance descriptions. It can identify a bundle within which provenance descriptions can be found. It may further identify a service, or may offer a IRI where provenance descriptions can be found.
A
provenance locator,
written
hasProvenanceIn(id, subject, bundle, target, attrs), has:
- id: an identifier for a provenance locator;
- subject: an identifier denoting something (entity, activity, agent, or relation instance);
- bundle: an optional identifier (bundle) for a bundle;
- target: an optional identifier (target) denoting something described in another set of descriptions (referred to as Target-URI in [PROV-AQ]);
- attributes: an optional set (attrs) of attribute-value pairs representing additional information about this locator; it optionally includes
prov:service-uri
or
prov:provenance-uri.
If the target is not specified, it is assumed that target is the same identifier as subject.
When the subject and optional target denote entities,
a provenance locator not only provides a located context, but it also expresses an alternate relation between the entity denoted by subject and the entity described in the located context. This is an alternate since the entity denoted by subject in the current context presents other aspects than the entity in the located one.
According to the following provenance locator, provenance descriptions about ex:report1 can be found in bundle bob:bundle1.
hasProvenanceIn(ex:report1, bob:bundle1, -)
According to the following provenance locator, provenance descriptions about ex:report1 can be found in bundle bob:bundle1, which is available from the provenance service identified by the provided URI.
hasProvenanceIn(ex:report1, bob:bundle1, -, [ prov:service-uri="http://example.com/service" %% xsd:anyURI ])
Let us again consider the same scenario involving two entities ex:report1 and ex:report2.
The first bundle can be expressed with all Bob's observations about the creation of ex:report1.
bundle bob:bundle4
entity(ex:report1, [ prov:type="report", ex:version=1 ])
wasGeneratedBy(ex:report1, -, 2012-05-24T10:00:01)
endBundle
Likewise, Alice's observation about the derivation of ex:report2 from ex:report1, is expressed in a separate bundle.
bundle alice:bundle5
entity(ex:report1)
hasProvenanceIn(ex:report1, bob:bundle4, -)
entity(ex:report2, [ prov:type="report", ex:version=2 ])
wasGeneratedBy(ex:report2, -, 2012-05-25T11:00:01)
wasDerivedFrom(ex:report2, ex:report1)
endBundle
In bundle alice:bundle5, there is a description for entity ex:report1, and
a provenance locator pointing to bundle bob:bundle4.
The locator indicates that some provenance description for ex:report1 can be found in bundle bob:bundle4. The purpose of the locator is twofold. First, it allows for incremental navigation of provenance [PROV-AQ]. Second, it makes entity ex:report1 described in alice:bundle5 an alternate of ex:report1 described in bob:bundle4.
Alternatively, Alice may have decided to use a different identifier for ex:report1.
bundle alice:bundle6
entity(alice:report1)
hasProvenanceIn(alice:report1, bob:bundle4, ex:report1)
entity(ex:report2, [ prov:type="report", ex:version=2 ])
wasGeneratedBy(ex:report2, -, 2012-05-25T11:00:01)
wasDerivedFrom(ex:report2, alice:report1)
endBundle
Alice can specify the target in the provenance locator to be ex:report1.
With such a statement, Alice states that provenance information about alice:report1 can be found in bundle
bob:bundle4 under the name ex:report1. In effect, alice:report1 and ex:report1 are declared to be alternate.
Consider the following bundle of descriptions, in which derivation and generations have been identified.
bundle obs:bundle7
entity(ex:report1, [prov:type="report", ex:version=1])
wasGeneratedBy(ex:g1; ex:report1,-,2012-05-24T10:00:01)
entity(ex:report2, [prov:type="report", ex:version=2])
wasGeneratedBy(ex:g2; ex:report2,-,2012-05-25T11:00:01)
wasDerivedFrom(ex:d; ex:report2, ex:report1)
endBundle
entity(obs:bundle7, [ prov:type='prov:Bundle' ])
wasAttributedTo(obs:bundle7, ex:observer01)
Bundle
obs:bundle7 is rendered by a visualisation tool. It may useful for the tool configuration for this bundle to be shared along with the provenance descriptions, so that other users can render provenance as it was originally rendered. The original bundle obviously cannot be changed. However, one can create a new bundle, as follows.
bundle tool:bundle8
entity(tool:bundle8, [ prov:type='viz:Configuration', prov:type='prov:Bundle' ])
wasAttributedTo(tool:bundle8, viz:Visualizer)
entity(ex:report1, [viz:color="orange"]) // ex:report1 is a reused identifier
hasProvenanceIn(ex:report1, obs:bundle7, -)
entity(tool:r2, [viz:color="blue"]) // tool:r2 is a new identifier
hasProvenanceIn(tool:r2, obs:bundle7, ex:report2)
wasDerivedBy(ex:d; ex:report2, ex:report1, [viz:style="dotted"])
hasProvenanceIn(ex:d, obs:bundle7, -)
endBundle
In bundle tool:bundle8, the prefix viz is used for naming visualisation-specific attributes, types or values.
Bundle tool:bundle8 is given type viz:Configuration to indicate that it consists of descriptions that pertain to the configuration of the visualisation tool. This type attribute can be used for searching bundles containing visualization-related descriptions.
For the purpose of illustration, we show that the visualisation tool
reused identifier ex:report1, but created a new identifier tool:r2.
They denote entities which are alternates of with ex:report1 and ex:report2, described in bundle obs:bundle7, with visualization attribute for the color to be used when rendering these entities.
Likewise, the derivation has a style attribute.
According to their definition,
derivations have an optional identifier.
To express an alternate for a derivation, we need to be able to reference it, by means of an identifier. Hence, it is necessary for it to have an identifier in the first place (ex:d).