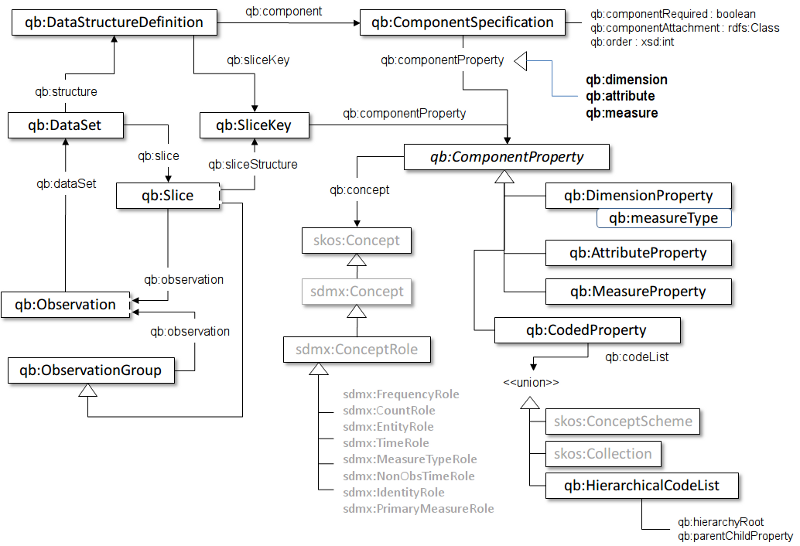
An instance of an RDF Data Cube should conform to a set of
integrity constraints which we define in this section.
Integrity constraints
Each integrity constraint is expressed as narrative prose and, where possible, a SPARQL
[[!sparql11-query]] ASK query or query template. If the ASK query is applied to an RDF graph then it
will return true if that graph contains one or more Data Cube instances which
violate the corresponding constraint.
Using SPARQL queries to
express the integrity constraints does not imply that integrity
checking must be performed this way. Implementations are free
to use alternative query formulations or alternative implementation
techniques to perform equivalent checks.
Each integrity constraint query assumes the following set of prefix bindings:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
The complete set of constraints is listed below.
IC-0. Datatype consistency
The RDF graph must be consistent under RDF D-entailment [[!RDF-MT]]
using a datatype map containing all the datatypes used within the graph.
IC-1. Unique DataSet
Every qb:Observation has exactly one associated qb:DataSet.
ASK {
{
# Check observation has a data set
?obs a qb:Observation .
FILTER NOT EXISTS { ?obs qb:dataSet ?dataset1 . }
} UNION {
# Check has just one data set
?obs a qb:Observation ;
qb:dataSet ?dataset1, ?dataset2 .
FILTER (?dataset1 != ?dataset2)
}
}
|
IC-2. Unique DSD
Every qb:DataSet has exactly one associated qb:DataStructureDefinition.
ASK {
{
# Check dataset has a dsd
?dataset a qb:DataSet .
FILTER NOT EXISTS { ?dataset qb:structure ?dsd . }
} UNION {
# Check has just one dsd
?dataset a qb:DataSet ;
qb:structure ?dsd1, ?dsd2 .
FILTER (?dsd1 != ?dsd2)
}
}
|
IC-3. DSD includes measure
Every qb:DataStructureDefinition must include at least one declared measure.
ASK {
?dsd a qb:DataStructureDefinition .
FILTER NOT EXISTS { ?dsd qb:component [qb:componentProperty [a qb:MeasureProperty]] }
}
|
IC-4. Dimensions have range
Every dimension declared in a qb:DataStructureDefinition must have a declared rdfs:range.
ASK {
?dim a qb:DimensionProperty .
FILTER NOT EXISTS { ?dim rdfs:range [] }
}
|
IC-5. Concept dimensions have code lists
Every dimension with range skos:Concept must have a qb:codeList.
ASK {
?dim a qb:DimensionProperty ;
rdfs:range skos:Concept .
FILTER NOT EXISTS { ?dim qb:codeList [] }
}
|
IC-6. Only attributes may be optional
The only components of
a qb:DataStructureDefinition that may be marked as
optional, using qb:componentRequired are attributes.
ASK {
?dsd qb:component ?componentSpec .
?componentSpec qb:componentRequired "false"^^xsd:boolean ;
qb:componentProperty ?component .
FILTER NOT EXISTS { ?component a qb:AttributeProperty }
}
|
IC-7. Slice Keys must be declared
Every qb:SliceKey must be associated with a qb:DataStructureDefinition.
ASK {
?sliceKey a qb:SliceKey .
FILTER NOT EXISTS { [a qb:DataStructureDefinition] qb:sliceKey ?sliceKey }
}
|
IC-8. Slice Keys consistent with DSD
Every qb:componentProperty on a qb:SliceKey must also be declared as a qb:component of the associated qb:DataStructureDefinition.
ASK {
?slicekey a qb:SliceKey;
qb:componentProperty ?prop .
?dsd qb:sliceKey ?slicekey .
FILTER NOT EXISTS { ?dsd qb:component [qb:componentProperty ?prop] }
}
|
IC-9. Unique slice structure
Each qb:Slice must have exactly one associated qb:sliceStructure.
ASK {
{
# Slice has a key
?slice a qb:Slice .
FILTER NOT EXISTS { ?slice qb:sliceStructure ?key }
} UNION {
# Slice has just one key
?slice a qb:Slice ;
qb:sliceStructure ?key1, ?key2;
FILTER (?key1 != ?key2)
}
}
|
IC-10. Slice dimensions complete
Every qb:Slice must have a value for every dimension declared in its qb:sliceStructure.
ASK {
?slice qb:sliceStructure [qb:componentProperty ?dim] .
FILTER NOT EXISTS { ?slice ?dim [] }
}
|
IC-11. All dimensions required
Every qb:Observation has a value for each dimension declared in its associated qb:DataStructureDefinition.
ASK {
?obs qb:dataSet/qb:structure/qb:component/qb:componentProperty ?dim .
?dim a qb:DimensionProperty;
FILTER NOT EXISTS { ?obs ?dim [] }
}
|
IC-12. No duplicate observations
No two qb:Observations in the same qb:DataSet may have the same value for all dimensions.
ASK {
FILTER( ?allEqual )
{
# For each pair of observations test if all the dimension values are the same
SELECT (MIN(?equal) AS ?allEqual) WHERE {
?obs1 qb:dataSet ?dataset .
?obs2 qb:dataSet ?dataset .
FILTER (?obs1 != ?obs2)
?dataset qb:structure/qb:component/qb:componentProperty ?dim .
?dim a qb:DimensionProperty .
?obs1 ?dim ?value1 .
?obs2 ?dim ?value2 .
BIND( ?value1 = ?value2 AS ?equal)
} GROUP BY ?obs1 ?obs2
}
}
|
IC-13. Required attributes
Every qb:Observation has a value for each declared attribute that is marked as required.
ASK {
?obs qb:dataSet/qb:structure/qb:component ?component .
?component qb:componentRequired "true"^^xsd:boolean ;
qb:componentProperty ?attr .
FILTER NOT EXISTS { ?obs ?attr [] }
}
|
IC-14. All measures present
In a qb:DataSet which does not use a Measure dimension then each individual qb:Observation must have a value for every declared measure.
ASK {
# Observation in a non-measureType cube
?obs qb:dataSet/qb:structure ?dsd .
FILTER NOT EXISTS { ?dsd qb:component/qb:componentProperty qb:measureType }
# verify every measure is present
?dsd qb:component/qb:componentProperty ?measure .
?measure a qb:MeasureProperty;
FILTER NOT EXISTS { ?obs ?measure [] }
}
|
IC-15. Measure dimension consistent
In a qb:DataSet which uses a Measure dimension then each qb:Observation must have a value for the measure corresponding to its given qb:measureType.
ASK {
# Observation in a measureType-cube
?obs qb:dataSet/qb:structure ?dsd ;
qb:measureType ?measure .
?dsd qb:component/qb:componentProperty qb:measureType .
# Must have value for its measureType
FILTER NOT EXISTS { ?obs ?measure [] }
}
|
IC-16. Single measure on measure dimension observation
In a qb:DataSet which uses a Measure dimension then each qb:Observation must only have a value for one measure (by IC-15 this will be the measure corresponding to its qb:measureType).
ASK {
# Observation with measureType
?obs qb:dataSet/qb:structure ?dsd ;
qb:measureType ?measure ;
?omeasure [] .
# Any measure on the observation
?dsd qb:component/qb:componentProperty qb:measureType ;
qb:component/qb:componentProperty ?omeasure .
?omeasure a qb:MeasureProperty .
# Must be the same as the measureType
FILTER (?omeasure != ?measure)
}
|
IC-17. All measures present in measures dimension cube
In a qb:DataSet which uses a Measure dimension then if there is a Observation for some combination of non-measure dimensions then there must be other Observations with the same non-measure dimension values for each of the declared measures.
ASK {
{
# Count number of other measures found at each point
SELECT ?numMeasures (COUNT(?obs2) AS ?count) WHERE {
{
# Find the DSDs and check how many measures they have
SELECT ?dsd (COUNT(?m) AS ?numMeasures) WHERE {
?dsd qb:component/qb:componentProperty ?m.
?m a qb:MeasureProperty .
} GROUP BY ?dsd
}
# Observation in measureType cube
?obs1 qb:dataSet/qb:structure ?dsd;
qb:dataSet ?dataset ;
qb:measureType ?m1 .
# Other observation at same dimension value
?obs2 qb:dataSet ?dataset ;
qb:measureType ?m2 .
FILTER NOT EXISTS {
?dsd qb:component/qb:componentProperty ?dim .
FILTER (?dim != qb:measureType)
?dim a qb:DimensionProperty .
?obs1 ?dim ?v1 .
?obs2 ?dim ?v2.
FILTER (?v1 != ?v2)
}
} GROUP BY ?obs1 ?numMeasures
HAVING (?count != ?numMeasures)
}
}
|
IC-18. Consistent data set links
If a qb:DataSet D has a qb:slice S, and S has an qb:observation O, then the qb:dataSet corresponding to O must be D.
ASK {
?dataset qb:slice ?slice .
?slice qb:observation ?obs .
FILTER NOT EXISTS { ?obs qb:dataSet ?dataset . }
}
|
IC-19. Codes from code list
If a dimension property has a qb:codeList, then the value of the dimension property on every qb:Observation must be in the code list.
The following integrity check queries must be applied to an RDF graph which contains the
definition of the code list as well as the Data Cube to be checked. In the case
of a skos:ConceptScheme then each concept must be linked to the scheme using
skos:inScheme. In the case of a skos:Collection then the
collection must link to each concept (or to nested collections) using skos:member. If the
collection uses skos:memberList then the entailment of skos:member
values defined by S36
in [[!SKOS-REFERENCE]] must be materialized before this check is applied.
ASK {
?obs qb:dataSet/qb:structure/qb:component/qb:componentProperty ?dim .
?dim a qb:DimensionProperty ;
qb:codeList ?list .
?list a skos:ConceptScheme .
?obs ?dim ?v .
FILTER NOT EXISTS { ?v a skos:Concept ; skos:inScheme ?list }
}
ASK {
?obs qb:dataSet/qb:structure/qb:component/qb:componentProperty ?dim .
?dim a qb:DimensionProperty ;
qb:codeList ?list .
?list a skos:Collection .
?obs ?dim ?v .
FILTER NOT EXISTS { ?v a skos:Concept . ?list skos:member+ ?v }
}
|
IC-20. Codes from hierarchy
If a dimension property has
a qb:HierarchicalCodeList with a
non-blank qb:parentChildProperty then the value of
that dimension property on every qb:Observation
must be reachable from a root of the hierarchy using zero or more hops along the qb:parentChildProperty links.
This check cannot be made by a simple fixed SPARQL query. Instead a
query template is supplied.
An instance of the template should be generated
for each qb:HierarchicalCodeList which has an IRI
value for its qb:parentChildProperty.
That is for each binding of ?p in the following
instantiation query:
SELECT ?p WHERE {
?hierarchy a qb:HierarchicalCodeList ;
qb:parentChildProperty ?p .
FILTER ( isIRI(?p) )
}
The template is then instantiated by replacing the
string $p by the IRI found by the
instantiation query. The template is:
ASK {
?obs qb:dataSet/qb:structure/qb:component/qb:componentProperty ?dim .
?dim a qb:DimensionProperty ;
qb:codeList ?list .
?list a qb:HierarchicalCodeList .
?obs ?dim ?v .
FILTER NOT EXISTS { ?list qb:hierarchyRoot/<$p>* ?v }
}
|
IC-21. Codes from hierarchy (inverse)
If a dimension property has
a qb:HierarchicalCodeList with an
inverse qb:parentChildProperty then the value of
that dimension property on every qb:Observation
must be reachable from a root of the hierarchy using zero or more hops along the inverse qb:parentChildProperty links.
This check cannot be made by a simple fixed SPARQL query. Instead a
query template is supplied.
An instance of the template should be generated
for each qb:HierarchicalCodeList which has a blank-node
value for its qb:parentChildProperty, with an
associated inverse property.
That is for each binding of ?p in the following
instantiation query:
SELECT ?p WHERE {
?hierarchy a qb:HierarchicalCodeList;
qb:parentChildProperty ?pcp .
FILTER( isBlank(?pcp) )
?pcp owl:inverseOf ?p .
FILTER( isIRI(?p) )
}
The template is then instantiated by replacing the
string $p by the IRI found by the
instantiation query. The template is:
ASK {
?obs qb:dataSet/qb:structure/qb:component/qb:componentProperty ?dim .
?dim a qb:DimensionProperty ;
qb:codeList ?list .
?list a qb:HierarchicalCodeList .
?obs ?dim ?v .
FILTER NOT EXISTS { ?list qb:hierarchyRoot/(^<$p>)* ?v }
}
|